iSeries
Trigger Techniques Re-Visited
by Alex Jayasundara
and Thibault Dambrine
Think of a hypothetical situation where a system has been
running for many years, with some "known bugs, but nothing too
critical". Consequences? Minor - One of the senior programmers simply runs
a quick scan program and fixes a few records once in a while. It is a problem,
a "known bug", but the company can survive without too much of a
hiccup. Sounds familiar?
What if the consequences were MAJOR? What if individual bank
accounts were at stake? Actual people's paychecks could be affected? How can
one make an application bug-proof? Bug-proofing any application, especially
complex and sensitive programs such as ones affecting payrolls, medical records
or banking records is not a trivial task. One giant step towards increasing
reliability by killing obvious bugs can be achieved with triggers.
Trigger programs typically are simple and automatically
activated. They enforce simple rules, such as "don't allow creation of a
detail record without an existing header" or "don't allow a money transfer for an amount
greater than what is available in the source account". They can also be more sophisticated, look at
related records in a number of other files before deciding to take action,
which itself can be a number of things, from writing a log record to preventing
an action or sending a message.
The point here is that simply said, bigger bugs tend to
occur less often if the more obvious ones are kept in check.
While the general principle of triggers has not changed
much, over time the AS/400 has become the iSeries, languages used on this
machine have evolved, and so have trigger techniques. So, get a cup of coffee, have a seat, and we
will show you with a few examples how you too can use triggers to make your
systems more reliable.
Trigger Basics
The official, IBM definition of a database trigger is as
follows:
Triggers are user-written programs that are associated with
database tables. You can define a trigger for update, delete, and insert
operations. Whenever the operation takes place, regardless of the interface
that is changing the data, the trigger program is automatically activated by
DB2 database and executes its logic. In this way, complex rules can be
implemented at the database level, totally independent from the application
layer.
Triggers are mainly intended for monitoring database changes
and taking appropriate actions. The main advantage of using triggers, instead
of calling the program from within an application, is that triggers are
activated automatically, regardless of the process at the origin of the data
change.
In addition, once a trigger is in place, application
programmers and end users cannot circumvent it. When a trigger is activated,
the control shifts from the application program to the database manager. The
operating system executes the trigger program to perform the actions you
designed. The application has no choice but to wait until the trigger program
has finished its job and only then gets control again.
Triggers may cause other triggers to be called. This is a
consideration one has to understand when designing triggers, which affect files
that are themselves equipped with triggers.
Type of Triggers
There are two types of triggers available in iSeries
database tables. They are SQL triggers and External triggers.
SQL triggers can be created using the SQL CREATE TRIGGER
statement. Part of the task when using SQL to create a trigger involves
specifying the name of the trigger, what table it is attached to, when it
should be activated (BEFORE INSERT, AFTER UPDATE etc), and finally what actions
it should perform. Using the SQL statement provided, the operating system will
create a C program with your SQL statements embedded within. In effect, the
system will do a combination of CRTSQLCI and CRTPGM commands to produce the
final trigger program. What will be visible to the user will be an ILE C *PGM
object.
External triggers are more conventional user written
programs. They may or may not contain SQL statements. External triggers can be
created using any high level language capable of generating *PGM objects. Each
programming language has its own strengths and weaknesses. It is up to the
programmer to select the optimal programming language to begin with. Since
external triggers start life as regular programs, they have to be manually
attached to a file to be implemented as triggers. This can be done with either
ADDPFTRG command or with the iSeries Navigator.
On the topic of iSeries languages in particular, SQL is emerging
as the more universal database access language. The iSeries has seen its SQL
abilities grow in the last few years. C is emerging as the language of choice
for applications that demand more portability. Finally, RPG did evolve in the
last 8 years. In this article we will
discuss triggers using pure SQL (SQL Triggers) and External triggers using RPG
and C. On that particular point, we will
use both SQL and conventional OS/400 terminology interchangeably in this
article. Appendix 1 gives the equivalent terminology for both.
Benefit of Triggers
Typical use of triggers include:
Ø
Provide
consistent auditing
Ø
Prevent
invalid transactions
Ø
Enforce
complex business rules
Ø
Enforce
complex security authorizations
Ø
Provide
automatic event logging
Ø Automatically generate derived
column values Preserving data consistency
across different database tables
Ø Data
validation and audit trail
Regardless of the application and the use one can make of the trigger,
the principles remain the same. The trigger fires on a given condition, say, a
deletion or the addition of a new record. When this happens, the contents of
the old and the new record are passed to the trigger program and the same
decision, the same rules and the same actions are taken every time, regardless
of what process modified the content of the file. Note that because trigger
programs will be fired for a number of circumstances, they should be very well
tested, as buggy trigger programs can create giant size messes, depending on
what they do.
Automated Teller Machine transaction
logging system Example
To illustrate triggers in the real world, we will use an
every-day life example: depositing or withdrawing money through ATM. Using that
example, we will explore the following scenarios:
The iSeries is writing Automated Teller Machine transactions
by writing add/change/delete row(s) to a transaction file named ATMTXN. The
table ATMTXN is equipped with a trigger. For each operation on ATMTXN the
trigger will log the transaction to a file named ATMTXNLOG.
While our example will only do logging, this solution can be
easily enhanced to update account balances, maintain ATM totals or perform
other outside operations.
The base of our example resides in two files: The
transaction file, ATMTXN, and the logging file, ATMTXNLOG. Here are the DDS
maps for these two files:
|
* ATM Transactions
UNIQUE R
ATMTRANR
ATMID 5A COLHDG('ATM ID')
ACCTID 5A COLHDG('Account #')
TCODE 1A COLHDG('Txn Code')
AMOUNT 7S 2 COLHDG('Txn Amount') DESC 10A COLHDG('Txn Description')
ALWNULL K
ATMID
K ACCTID |
DDS for ATMTXN
The fields
in ATMTXN are self-explanatory. Note the ALWNULL keyword on field DESC, which
will allow this field to contain NULL's. We made DESC field as null-capable to
be able to explore the topic of NULL maps in relationship with their purpose
when using triggers.
ATMTXNLOG
|
* ATM
Transactions log R TXNLOGR
LOPER 1A COLHDG('Operation') LDATE L COLHDG('Date') LTIME T COLHDG('Time') LIMGB 28A COLHDG('Before Image') LNMAPB 5A COLHDG('Null Map - Before') LIMGA 28A COLHDG('After Image') LNMAPA 5A COLHDG('Null Map - After') |
DDS for ATMTXNLOG
IN ATMTXNLOG,
-
Field
LOPER will contain a transaction code (I
insert, U update, D delete) to identify the type of operation.
-
LDATE
and LTIME will hold the date and time of the transaction.
-
LIMGB
and LNMAPB will hold the record before the operation and null map before the
operation respectively
-
LIMGA
and LNMAPA are the corresponding fields for after the operation.
-
LNMAPB
and LNMAPA fields will contain the NULL MAPS for each of the record images.
NULL maps are sequences of ones and zeros used to indicate the presence of null
values in the field they represent. There are as many bytes in the NULL map as
there are fields. Encountering a NULL value in a field can make a high level
program crash. The trigger program can use the NULL Map to know in advance if a
field contains NULLs. The idea is to enable program logic based on the value of
the NULL indicator rather than attempting to use a NULL-filled field which
would make it crash.
Overview of the Design
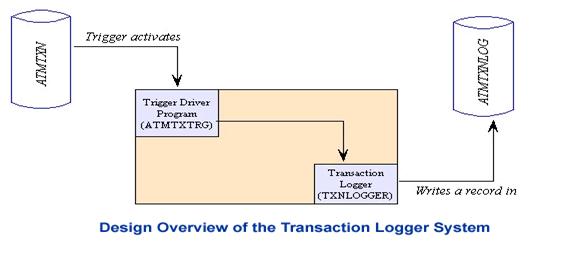
The diagram above shows that when any modification is made
to ATMTXN, the system will invoke the trigger program named ATMTXTRG. ATMTXTRG
will capture the old record, the old null map, the new record and the new null
map. It will then write these fields in the TXNLOGGER, along with the NULL
maps. This design was selected to facilitate the discussion of ATMTXTRG using
different languages (RPG and C), that have comparable features. Later, we will
discuss the same trigger example, using SQL this time, to do the job.
Basic information for trigger
programming
When a trigger is fired, the system provides two key
elements for trigger program. They are the Trigger Buffer and the Trigger
Buffer Length. An important point is that the Trigger buffer contains both a
static area and a dynamic area. More details on the trigger buffer and its
sub-fields can be found in the DB2 UDB for iSeries Database Programming V5R1.
Here is a graphic picture of what this buffer looks like:
10 20 30 31 32 33 36 40 44 48
|
Physical File
Name |
Library
Name |
Member
Name |
Trig. Event |
Trig. Time |
Cmt Level |
|
CCSID |
Relative Rec.
# |
|
64
80 96
|
Old
Record Information |
New
Record Information |
|
|
||||||
|
Offset |
Length |
|
Null Map Offset |
Null Map Length |
Offset |
Length |
Null Map Offset |
Null Map Length |
|
|
|
Old Record |
|
Old Record Null Map |
|
New Record |
|
New Record Null Map |
|
|
|
Trigger
Buffer This buffer
will be passed to the external trigger program
|
|
Reserved by IBM for future use |
In the trigger buffer, position 1 to 44 contains physical file
information. This information may be useful in some circumstances, for example
if the trigger monitors for the size of the file or if the trigger program has
a decision to make based on the member being used. Position 49 to 80 however
tends to be the bread and butter information for most trigger programs.
Starting at position 49, you will find four fields, which can be better
qualified as pointers. They contain offsets and lengths for "old" or
before image of the record being modified and its corresponding null map. The
same pointers for new record can be found at position 65. This whole area of
the trigger buffer (position 0 thru 96) is called as static area.
Following the static area, in a variable position (you will
notice the diagram does not specify a position), is the dynamic area. This area
will contain the before and after records and their corresponding NULL maps.
This is most commonly the actual data that any trigger program will use to make
a decision.
Before V5R1 the before and after record images were placed
soon after the position 96. While this sounds ambiguous, there is a reason.
Here is how it used to work: . So if you had a file with F number of fields and
a record length of L, then the total length of the trigger buffer would be 96 +
2 * (L + F). In effect, the static and dynamic parts of the trigger buffer were
contiguous.
After V5R1, the dynamic portion of the trigger buffer may
not come immediately after the static portion of the buffer. Note that in
potentially, these fields can be change on every execution of the trigger for
the same file even if the field definitions did not change.
Based on above facts there is no way to access the dynamic
area correctly unless we use the information on position 49 thru 80 to find
where the dynamic portion of the data is located.
Because of this change, most trigger programs written prior
to V5R1 are not working well after V5R1. In this article we will assume that
all four dynamic data is placed in the different locations and will use the pointers
from position 65 thru 80 to determine the starting positions as follows.
Another notable V5R1 change is that IBM has removed the previous limit of 6
triggers per table since V5R1. Now one database table can have maximum of 300
triggers.
|
Starting position of old
record = Starting position of trigger buffer + Old
record offset
(value from position 49 52) Starting position of new
record = Starting position of trigger buffer + New
record offset
(value from position 64 67) Starting position of old null
map =
Starting position of trigger buffer + Old null map offset
(value from position 57 60) Starting position of new null
map =
Starting position of trigger buffer + new null map offset (value from position 73 76) |
Trigger Example using RPG ILE
When writing any trigger program, the first order of the day
is defining the trigger buffer. Here below is the definition of the trigger
buffer for RPG. Here is the definition for this example:
|
D* D* Data structures for Trigger Buffer D* and Trigger Buffer Length D* D* Trigger Buffer D* DTrgBuffer DS D TFileName 10 D TLibName 10 D TMemName 10 D TTrgEvent 1 D TTrgTime 1 D
TCommitLock 1 D TFiller1 3 D TCCSID 10I 0 D TRelRecNbr 10I 0 D TFiller2 10I 0 D TOldRecOff 10I 0 D TOldRecLen 10I 0
D
TOldNullOff 10I
0 D
TOldNullLen 10I
0 D TNewRecOff 10I 0 D TNewRecLen 10I 0 D
TNewNullOff 10I
0 D
TNewNullLen 10I 0 D* D* Trigger Buffer Length D*
DTrgBufferLen S 10I 0 |
Trigger Buffer for RPG
Note the
use of I (integer) data type for all the binary data types. This is because
integer data type is more efficient and supports full range of values possible.
One useful technique is to define the trigger buffer data structure as a
separate source member. It can then be used with a COPY statement in any
trigger program. We saved the above as TRGBUFFER with the type DS (for Data
Structure) and it will be included in our ATMTXTRG RPG version.
Here is
the RPG portion of ATMTXTRG. For clearer understanding, we will break it down
in five parts:
Part 1 Defining the trigger buffer
and other variables.
|
*.
1 ...+... 2 ...+... 3 ...+... 4 ...+... 5 ...+... 6 ... ***************
Beginning of data ************************* D*
D/COPY
QRPGLESRC,TRGBUFFER D*
|
The only
line in the code above will copy our trigger buffer to the program at time of
compilation.
Part 2 Declaring data storage for
old and new records
To
declare structures describing the before and after images of the records
monitored by the trigger program, there is a good shortcut available in ILE
RPG: Use the file name to serve as an externally defined data structure. We are
going to use Extname keyword to
define the external file name and Prefix
keyword for global renaming of all fields in the database file. It is important
to distinguish fields from new and old records if you are using your driver
program to initiate specific tasks based on specific information (eg. Send a
notification for a withdrawal over certain amount).
|
*. 1 ...+... 2 ...+... 3 ...+... 4 ...+...
5 ...+... 6 ...+... 7 D*
D*
Record format for New and Old Records. D*
D OldRecord E DS ExtName(ATMTXN) D
Prefix(O_) D
Based(OldRecPtr) D*
D NewRecord E DS ExtName(ATMTXN) D
Prefix(N_) D
Based(NewRecPtr) |
By
combining Prefix and ExtName keywords what program does is copy the fields of
ATMTXN with prefix O_ to the data structure OldRecord and copy the fields of
ATMTXN with prefix N_ to the data structure NewRecord. You will see this
reflected in the compilation listing.
The
keywords "Based" are used
to identify which pointer is used to access the data for a given data
structure. As soon as the pointers are populated with the required data, the
record information will be made available in the data structure.
Part 3 Declaring data storage for
old and new null maps
As a
reminder, the NULL maps contain a series of one-byte flags. There is one NULL
map byte per field and they are grouped in a data structure. Access to the NULL
map data structure will be done with the same method we used for the record
data. The length of the null map is always equal to number of fields in the
data base file (one byte per field). In this example, we declare an array with
the dimension of 5 one-byte elements since our file only has five data
fields.
|
DName+++++++++++ETDsFrom+++To/L+++IDc.Keywords+++++++++++++++++++++++++ D*
D* Record layout for New and Old Null
Maps. D*
D
OldNullMap DS Based(OldNullPtr) D ONullFld 1 DIM(5) D
NewNullMap DS Based(NewNullPtr) D NNullFld 1 DIM(5) D*
|
Here we
have defined two pointers named OldNullPtr and NewNullPtr to hold the
starting positions of the null maps and by setting the values for these
pointers data will be available on OldNullMap
and NewNullMap.
Part 4 Declaring the parameter list
The
trigger buffer and trigger buffer length will be passed to the program by the
system as parameters each time the trigger is fired. These parameters are
written in the most standard RPG.
|
CL0N01Factor1+++++++Opcode&ExtFactor2+++++++Result++++++++Len++D+HiLoEq
C *ENTRY PLIST
C PARM TrgBuffer C PARM TrgBufferLen C*
|
Part 5
Setting pointers
We will
use the RPG built in function %ADDR to supply the values to the pointers as
shown below. This will effectively populate the pointers that will tell the
program where to locate the data structures described in the sections above.
|
CL0N01Factor1+++++++Opcode&ExtExtended-factor2+++++++++++++++++++++++++++
C Eval OldRecPtr = %ADDR(TrgBuffer) + TOldRecOff C Eval NewRecPtr = %ADDR(TrgBuffer) + TNewRecOff C*
C Eval OldNullPtr = %ADDR(TrgBuffer) +
TOldNullOff C Eval NewNullPtr = %ADDR(TrgBuffer) +
TNewNullOff |
As soon
as the OldRecPointer is retrieved, data will be available in OldRecord. The same principle will apply to the other
combinations of pointers and data structures.
Having retrieved
the pointers and thus the associated data structures, the program now has
access to the before and after image of the record, broken up by field that can
be distinguished. By this, we mean that any of the old record fields can be
individually compared to its corresponding new version. The program is now
equipped with all the information necessary to write the logic within the
program.
The
example we have chosen to write here is a simple logging function. We could
have references to other, outside files, but for now, on with this example. The
trigger program will log the before and after images of the records modified,
along with their NULL maps and pass this information as parameters to a
separate program named TXNLOGGER.
|
C* C*
Call TXNLOGGER
C*
C CALL 'TXNLOGGER' C PARM TTrgEvent C PARM OldRecord C PARM OldNullMap C PARM NewRecord C PARM NewNullMap C*
C*
End the program
C* C Eval *InLR = *On C*
|
Code for TXNLOGGER
Using the parameters passed earlier on, TXNLOGGER will write
the actual log file record.
|
FATMTXNLOG
O A E DISK D* DInsert C CONST('1') DDelete C CONST('2') DUpdate C CONST('3') D* DTrgEvent S 1A DOldRecord S 28A
DOldNullMap S 5A DNewRecord S 28A
DNewNullMap S 5A D* DCurTime S T DCurDate S D D* D* C *ENTRY PLIST C PARM TrgEvent C PARM OldRecord C PARM OldNullMap C PARM NewRecord C PARM NewNullMap C* C* C TIME CurTime C TIME CurDate C* C MOVE CurDate LDATE C MOVE CurTime LTIME C* C Select C When TrgEvent = Insert C Move 'I' LOPER C MOVE NewRecord LIMGA C MOVE NewNullMap LNMAPA C* C When TrgEvent = Update C Move 'U' LOPER C MOVE OldRecord LIMGB C MOVE OldNullMap LNMAPB C MOVE NewRecord LIMGA C MOVE NewNullMap LNMAPA C* C When TrgEvent = Delete C Move 'D' LOPER C MOVE OldRecord LIMGB C MOVE OldNullMap LNMAPB C EndSl C* C Write TXNLOGR C Eval *InLR = *On |
Compiling Techniques for ATMTXTRG and
TXNLOGGER
In this example, we have split the
trigger process in two different programs, ATMTXTRG and TXNLOGGER.
Conceivably, one could do the entire
job with just one program. There are advantages and disadvantages for both
techniques. On the plus side, having two programs means that the ATMTXTRG
portion is very simple. If they had to be re-cycled as base code to write other
triggers, this code would be easy to modify.
One parameter to be careful about
when compiling trigger programs that are coded in two parts, like we have here,
is the activation group. For the trigger program it is most efficient to use
ACTGRP(*CALLER), which means the trigger driver program will share the
resources of its calling program, instead of starting a new activation group.
Here below are the compile commands
used to create the programs we have written above.
CRTRPGMOD MODULE(TRIGTEST/ATMTXTRG) SRCFILE(TRIGTEST/QRPGLESRC)
SRCMBR(ATMTXTRG)
CRTPGM
PGM(TRIGTEST/ATMTXTRG)
MODULE(TRIGTEST/ATMTXTRG)
ACTGRP(*CALLER)
CRTRPGMOD
MODULE(TRIGTEST/TXNLOGGER)
SRCFILE(TRIGTEST/QRPGLESRC) SRCMBR(TXNLOGGER)
CRTPGM
PGM(TRIGTEST/TXNLOGGER
MODULE(TRIGTEST/TXNLOGGER)
Adding trigger program to ATMTXN
With the two programs described
above, we now have the components of the trigger. The trigger however will not
call itself unless we create the link between the file and the trigger
programs. To do this, we will add ATMTXTRG as a trigger to ATMTXN database
file.
This can be done in one of three
methods. A trigger that will link our programs to the transaction file can be
added:
-
At
time of creation of the table.
-
Editing
the properties of the already existing transaction table using Operations
Navigator can do it.
-
The
CL command Add Physical File Trigger (ADDPFTRG) command can also be used to
link the transaction table with the trigger program. This is the most commonly
used method.
Before adding a trigger to a physical
file, ensure you have proper authority. See Appendix 1, Required authorities
and data capabilities for triggers for
information about these requirements.
In this case, we will use the most
common method used, the ADDPFTRG CL command.
ADDPFTRG
FILE(TRIGTEST/ATMTXN) TRGTIME(*AFTER)
TRGEVENT(*INSERT)
PGM(TRIGTEST/ATMTXTRG)
TRG(ATMTXN_RPG_AFTER_INSERT)
Note that in this example, the trigger will be fired after every
insert. We named the trigger ATMTXN_RPG_AFTER_INSERT. Using meaningful names for triggers is always helpful,
especially if there are multiple triggers on a single file.
Now that we have created the
association between the file and the trigger program, the system will call the
trigger program (this is often described as "fire the trigger") after
(in this case) each write, operation on any member of that physical file.
To verify that the trigger added is
well in place, use the command
DSPFD FILE(TRIGTEST/ATMTXN)
TYPE(*TRG)
It provides information such as the
number of trigger programs, trigger program names and libraries, trigger events
(add/update/delete) and the trigger time (before or after the events).
Once this verification is done, the
trigger process and the trigger program can be tested together.
Testing the trigger program
To test ATMTXTRG what needs to be done is either an add, a
change or a delete operation on ATMTXN, depending on how the trigger is configured.
In this case, the trigger will fire after an insert. If it everything is
correct, it should fire the trigger when a new record is written to the
transaction file and the log record should be found in the ATMTXNLOG file.
One convenient way to test and
document the tests done is to use SQL Statements, DFU and other simple data
entry applications for the iSeries are also good, but they lack the
"documentable" of SQL. No matter how you change the data trigger will
be activated and records will be logged. The fact that the trigger is fired, no
matter what program touches the file, is the most important feature of a
trigger. Here are some SQL examples that you can use if you are trying for
yourself to fire the trigger in this example.
INSERT INTO TRIGTEST/ATMTXN VALUES ('ATM01','10001', 'W', 100.00,
'TEST ' )
INSERT INTO
TRIGTEST/ATMTXN VALUES
('ATM02','20001', 'D', 230.00, NULL )
UPDATE TRIGTEST/ATMTXN SET DESC = 'NOT
NULL' WHERE ATMID = 'ATM02'
DELETE FROM TRIGTEST/ATMTXN WHERE ATMID = 'ATM03'
After running the above commands
have a look at the file ATMTXNLOG. You will see the transactions you have
entered automatically reproduced in the transaction log file the trigger. If
you carefully view the log record for second transaction you will see 00001 as
your null map. What it says is fifth field was null. At the same time log
record for third transaction will hold 00001 for null map before update and
00000 for null map after update. This says the fifth field was NULL before and
now it is not a null field.
Trigger Example using ILE C
We will use same five steps that we
have used in the RPG example to explain our C trigger program. Lets start from
trigger buffer. Here is they way you would define the trigger buffer using C:
|
/* Trigger
Buffer */ struct Trg_Buffer{ char
TFileName[10]; char
TLibName[10]; char
TMbrName[10]; char
TTrgEvent[1]; char
TTrgTime[1]; char
TCmtLvl[1]; char
TResv01[3]; int
CCSID; int
Current_RRN; char
TResv02[4]; int
TOldRecOffset; int
TOldRecLength; int
TOldNullMapOffset; int
TOldNullMapLen; int
TNewRecOffset; int
TNewRecLength; int
TNewNullMapOffset; int
TNewNullMapLen; } TrgBuf; |
Trigger Buffer for C
Note that this is an explicit description
of the trigger buffer. Another technique consists of using a header file
provided by IBM. The code would look like
#include
"qsysinc/h/trgbuf" /* Trigger input parameter */
We saved this trigger buffer in a
source file TRGBUFFER. Here is the complete source listing divided into five
sections.
|
#include
<stdio.h>
#include
<stdlib.h>
A #include
<string.h> #include
"TRGBUFFER"
#pragma
map(write_atm_log, "TXNLOGGER") #pragma
linkage(write_atm_log, OS, nowiden) void
write_atm_log(char[1], char[28], char[28], char[5], char[5]); #define RECSIZE
28
#define FLDTOTAL
5 void
trgbufcpy(char *, char *, int, int); |
|
void
main(int argc, char **argv) B {
char buf_before[RECSIZE]; char
buf_after[RECSIZE]; char nullmap_before[FLDTOTAL]; char nullmap_after[FLDTOTAL]; |
|
memcpy(&TrgBuf, argv[1],
sizeof(TrgBuf)); C
trgbufcpy(argv[1], buf_before,
TrgBuf.TOldRecOffset,
TrgBuf.TOldRecLength);
Trgbufcpy(argv[1], buf_after,
TrgBuf.TNewRecOffset,
TrgBuf.TNewRecLength);
Trgbufcpy(argv[1], nullmap_before,
TrgBuf.TOldNullMapOffset, TrgBuf.TOldNullMapLen);
trgbufcpy(argv[1], nullmap_after,
TrgBuf.TNewNullMapOffset, TrgBuf.TNewNullMapLen); |
|
write_atm_log(TrgBuf.TTrgEvent, D buf_before, nullmap_before, buf_after, nullmap_after); } /* End of |
|
void
trgbufcpy(char *source_str, char *dest_str, int bufoffset, int buflen) E {
int i;
for (i = 0; i <= buflen; i++){ dest_str[I] = source_str[i +
bufoffset];
}
dest_str[buflen] = '\0';
} |
Complete source code for
trigger driver program (ATMTXTRG) using ILE C.
We will now dissect the C program to
expose the same five steps we used to build our RPG program.
Define
trigger buffer and other variables
In the code above, the first 3 lines
are standard C header files. The fourth line is a user include file. It is
distinguished by the quotations around
it. The next two lines define the Records Size and number of fields
respectively. The last line is the
prototype definition for the function trgbufcpy. This is a user-defined
function that we created for the purpose of copying the trigger buffer
contents. The combination of other C instructions can also be used, but in our
opinion, trgbufcpy makes processing clearer and easier to read. This function
takes four arguments: The source buffer (the incoming parameter), the
destination (the buffer we will use in the program), the offset (where we will
pick up the data) and the length (how many bytes we will copy in the buffer).
This was done in section A.
Declaring
data storage for old and new records and old and new null maps
The first two character arrays
declared above in section B will hold the before and after record images. The
next two will contain the before and after images of the null maps. In these
statements we used the predefined variables RECSIZE and FLDTOTAL defined in
section A.
Declaring
the parameter list
In C The first parameter, the
integer argc will hold the number of parameters passed to the program. The
parameters do not have to be declared separately. They will be passed via the
argv array.
Setting
pointers and copying data
This is done in section C. The first
line will copy the first parameter argv[1] to our trigger structure. Next four lines
will copy respective parts of the memory to variables buf_before, buf_after,
nullmap_before and nukmap_after. We are using the function trgbufcpy that we
declared in section A.
Now we have to call TXNLOGGER to log
the information. We cannot just make a call here. We have to define TXNLOGGER
program using #pragma keywords (this was
done in section A) and then call that mapped function. In our program TXNLOGGER
program was mapped to a function
write_atm_log.
Note: The activation group consideration for the C programs
are the same as the ones relevant the RPG programs. The only difference is that
instead of using CRTRPG commands, we will use CRTC commands.
Trigger Example using SQL
In the RPG and C examples, we used 5 distinct steps to
exemplify the trigger-building process. While SQL achieves the same goals, it
is more of a single pass type of process.
Here is the general structure of an trigger, when written with an SQL
statement:
CREATE
TRIGGER trigger_name
Activation
_Time
Trigger_Event ON table_name
REFERNENCING OLD AS old_row NEW AS new_row
FOR EACH ROW/ FOR EACH STATEMENT
MODE DB2ROW /DB2SQL
WHEN condition
BEGIN
Trigger body
END
Two key elements must be well
understood when using triggers in general and SQL triggers in particular:
The timing of the
trigger: BEFORE or AFTER
The operation that the
trigger will monitor for: INSERT, UPDATE or DELETE
When combined, these two parameters make
phrases like AFTER INSERT or BEFORE UPDATE etc.
If for example you are
planning to access fields present in a row BEFORE and AFTER the operation, you
should declare correlation variables for both the old row and the new row. In the
example above, such a variable referencing the before value would be named
old_row.fieldname, and it could be compared to new_row.fieldname in the trigger
body. This, in effect, is the way to refer to the before and after trigger
buffers in SQL.
Here below is the SQL
version of the RPG and C trigger example programs for an insert operation:
CREATE TRIGGER I_TRANSLOGGER
AFTER INSERT
ON ATMTXN
REFERENCING NEW_TABLE AS N_TABLE
NEW AS N_ROW
FOR EACH ROW MODE DB2SQL
INSERT INTO ATMTXNLOG
VALUES ('I', DATE(CURRENT TIMESTAMP),
TIME(CURRENT TIMESTAMP),
'NO BEFORE IMAGE ', 'DUMMY',
CHAR(N_ROW.ATMID)||CHAR(N_ROW.ACCTID)||
CHAR(N_ROW.TCODE)||
CHAR(N_ROW.AMOUNT)||
CHAR(N_ROW.DESC),
'DUMMY'
)
Let us highlight a few points on this statement:
The data that can be processed by an SQL trigger can be
looked at three different levels:
1)
The
individual row level, defined with the keyword "NEW"
2)
The
entire set of new transactions being inserted, defined with the keyword
"NEW_TABLE"
3)
The
entire set of old transactions being affected, defined with the keyword
"OLD_TABLE"
In this example, we defined both, but only used the NEW
level, defined here as N_ROW. Fields are referred to using N_ROW.FIELD_NAME.
The NEW_TABLE
keyword gives SQL access to what is known as the "TRANSITION TABLE". If necessary, one could use the values within
to insert aggregated logic, such as MIN,
MAX or AVG. To specify a Transition Table, the keyword REFERENCING is
being used in the CREATE TRIGGER statement.
Here below are the two possible TRANSITION TABLE statements usable:
New_Table Table Name
Specifies the name of
the table which captures the value that is used to update the rows in the database
when the triggering SQL operation is applied to the database. On an insert,
note that the Before Image is a NULL
OLD_TABLE
table-name
Specifies the name of the table which captures the original state of the set of
affected rows (that is, before the triggering SQL operation is applied to the
database).
In SQL, NULL Maps are not generated. We are using the same
file images in this example as the ones we used previously for C and RPG. In
this SQL example, the fields formerly filled with NULL maps are simply are filled
with the DUMMY constant. In SQL, the instruction IFNULL is the most
convenient way to insert a default value if a NULL value was present in a
field.
Other Trigger Examples using SQL
On an
Update:
We will use
only the amount field for update operation.
CREATE TRIGGER U_TRANSLOGGER
AFTER UPDATE OF AMOUNT ON ATMTXN
REFERENCING OLD AS O_ROW NEW AS N_ROW
FOR EACH ROW
WHEN (O_ROW.AMOUNT <> 0 and
N_ROW.AMOUNT < 0)
INSERT INTO ATMTXNLOG
VALUES ('U', DATE(CURRENT TIMESTAMP),
TIME(CURRENT TIMESTAMP),
'Account balance now below zero -
Activate Cheque Protection. Old Row Values:' ||
CHAR(O_ROW.ACCTID)||
CHAR(O_ROW.TCODE) || CHAR(O_ROW.AMOUNT),
'DUMMY',
' New Row Values:' ||
CHAR(N_ROW.ACCTID)||
CHAR(N_ROW.TCODE) || CHAR(N_ROW.AMOUNT),
'DUMMY')
On a
delete, note that the After Image is a NULL. We also don't need the NEW_TABLE
intermediate values.
CREATE TRIGGER D_TRANSLOGGER
AFTER DELETE OF TRIGTEST/ATMTXN
REFERENCING OLD AS O_ROW NEW AS
N_ROW
FOR EACH ROW MODE
DB2SQL
INSERT INTO
TRIGTEST/ATMTXNLOG
VALUES ('D',
DATE(CURRENT TIMESTAMP), TIME(CURRENT TIMESTAMP),
CHAR(N_ROW.ATMID) || CHAR(N_ROW.ACCTID)||
CHAR(N_ROW.TCODE)||
CHAR(N_ROW.AMOUNT)
|| CHAR(N_ROW.DESC),
'DUMMY',
CHAR(ATMID)||CHAR(ACCTID)||
CHAR(TCODE)||
CHAR(AMOUNT)|| CHAR(DESC),
'DUMMY' )
Note that
on a delete trigger, the After Image is a NULL. We also don't need the
NEW_TABLE intermediate values.
To block
actions, such as writing new records by using a trigger, the following code can
be used
CREATE TRIGGER BLOCK_INSERT
NO CASCADE BEFORE INSERT ON ATMTXN
REFERENCING NEW AS N_ROW
FOR EACH ROW MODE DB2SQL
WHEN (N_ROW.AMOUNT < 0 )
BEGIN ATOMIC
SIGNAL SQLSTATE '85101'
SET MESSAGE_TEXT = 'ATTEMPT TO MODIFY AN ACCOUNT WITH A NEGATIVE
BALANCE';
END
To delete a
trigger with SQL, use the DROP instruction:
ALTER
TABLE ATMTXN
DROP
TRIGGER TRANSLOGGER
Executing the SQL Trigger Code
Most of the
statements above can be executed by hand in the STRSQL command entry line, or
using RUNSQLSTM with the SQL statement stored in a source member. If however
your SQL statement is more complex, with WHILE constructs for example, you will
need to use either a procedure or embed your SQL statement in a high level
language like RPG or C.
Embedded SQL Considerations
So far, we have covered trigger techniques in RPG, in C and
in SQL. If you are in a situation where a mixture of a high level language and
SQL would be the best solution, that can also be used as a trigger. The
following example, a C program with embedded SQL code demonstrate, still using
our example files.
|
#include
<stdio.h> #include
<stdlib.h> #include
<string.h> #include
"TRIGTEST/QCSRC/TRGBUFFER" #pragma
mapinc("atmtxnlog","
TRIGTEST/ATMTXNLOG(TXNLOGR)","both","p z") #include
"atmtxnlog" #define FILESIZE
28 #define FLDTOTAL
5 EXEC SQL BEGIN DECLARE SECTION; char sbuf_before[28]; char sbuf_after[28]; char snull_before[5]; char snull_after[5]; char op_code[1]; EXEC SQL DECLARE :sbuf_before VARIABLE
FOR MIXED DATA; EXEC SQL DECLARE :sbuf_after VARIABLE
FOR MIXED DATA; EXEC SQL DECLARE :snull_before VARIABLE
FOR MIXED DATA; EXEC SQL DECLARE :snull_after VARIABLE
FOR MIXED DATA; EXEC SQL DECLARE :op_code VARIABLE FOR SBCS
DATA; EXEC SQL END DECLARE SECTION; exec sql include SQLCA; void
trgbufcpy(char *, char *, int, int); void main(int
argc, char **argv) { char buf_before[FILESIZE]; char buf_after[FILESIZE]; char nullmap_before[FLDTOTAL]; char nullmap_after[FLDTOTAL]; EXEC SQL WHENEVER SQLERROR GO TO
inform_error; memcpy(&TrgBuf, argv[1],
sizeof(TrgBuf)); trgbufcpy(argv[1], buf_before,
TrgBuf.TOldRecOffset,
TrgBuf.TOldRecLength); trgbufcpy(argv[1], buf_after,
TrgBuf.TNewRecOffset,
TrgBuf.TNewRecLength); trgbufcpy(argv[1], nullmap_before, TrgBuf.TOldNullMapOffset,
TrgBuf.TOldNullMapLen); trgbufcpy(argv[1], nullmap_after,
TrgBuf.TNewNullMapOffset,
TrgBuf.TNewNullMapLen); strcpy(sbuf_before, buf_before); strcpy(sbuf_after, buf_after); strcpy(snull_before, nullmap_before); strcpy(snull_after, nullmap_after); strcpy(op_code, TrgBuf.TTrgEvent); EXEC SQL INSERT INTO TRIGTEST/ATMTXNLOG VALUES (:op_code, CHAR(DATE(CURRENT
TIMESTAMP)), TIME(CURRENT
TIMESTAMP), :sbuf_before, :snull_before, :sbuf_after,
:snull_after); inform_error: EXEC SQL WHENEVER SQLERROR CONTINUE; printf("*** Error Occured.
SQLCODE = %5d\n",SQLCODE); EXEC SQL ROLLBACK; exit(0); } /* End of
void
trgbufcpy(char *source_str, char *dest_str, int bufoffset, int buflen) {
int i; for (i = 0; i <= buflen; i++){ dest_str[I] = source_str[i +
bufoffset];
}
dest_str[buflen] = '\0'; } |
Triggers and their relationship to referential
integrity
A physical
file can have both triggers and referential constraints associated with it. The
running order among trigger actions and referential constraints depends on the
constraints and triggers that associate with the file.
In some
cases, the system evaluates referential constraints before and after the system
calls a trigger program. This is the case with constraints that specify the
RESTRICT rule.
In some
cases, all statements in the trigger program -- including nested trigger
programs -- run before the constraint is applied. This is true for NO ACTION,
CASCADE, SET NULL, and SET DEFAULT referential constraint rules. When you
specify these rules, the system evaluates the file's constraints based on the
nested results of trigger programs. For example, an application inserts
employee records into an EMP file that has a constraint and trigger:
If a
referential constraint specifies that a department number for an inserted
employee record to the EMP file must exist in the DEPT file, whenever an insert
to the EMP file occurs, the trigger program checks if the department number
exists in the DEPT file. The trigger program then adds the number if it does
not exist.
When the
insertion to the EMP file occurs, the system calls the trigger program first.
If the department number does not exist in the DEPT file, the trigger program
inserts the new department number into the DEPT file. Then the system evaluates
the referential constraint. In this case, the insertion is successful because
the department number exists in the DEPT file.
There are
some restrictions when both a trigger and referential constraint are defined
for the same physical file:
Ø
If
a delete trigger associates with a physical file, that file must not be a
dependent file in a referential constraint with a delete rule of CASCADE.
Ø
If
an update trigger associates with a physical file, no field in this physical
file can be a foreign key in a referential constraint with a delete rule of SET
NULL or SET DEFAULT.
Ø
If
failure occurs during either a trigger program or referential constraint validation,
all trigger programs associated with the change operation roll back if all the
files run under the same commitment definition. The referential constraints are
guaranteed when all files in the trigger program and the referential integrity
network run under the same commitment definition. If you open the files without
commitment control or in a mixed scenario, unpredictable results may occur.
Ø
When
saving a file that is associated with a constraint, the database network saves
all dependent files in the same library.
Having said
that, there may be cases when creating a referential constraint may be less
effort than writing a trigger program. Simple rules can be enforced with this
method using very little coding. The caveat is, as always, in the inflexible
nature of a constraint, as opposed to a trigger, where for example, a user can
be notified rather than having a hard crash for an invalid update on a
referential constraint file. Here are some examples:
The
constraint shown here will prevent anyone from altering a bank balance with a
negative number.
ALTER TABLE ATMTXN
ADD CONSTRAINT NO_NEGATIVE_BAL
CHECK (AMOUNT > 0)
The
constraint below ensures that the value entered in the account number would
have to exist in the account master. In
addition, the delete rule specified in the VALID_ACCOUNT constraint is NO
ACTION, which means that an account record in the ACCT_MASTER table cannot be
deleted if there are records with that account number in the ATMTXN table.
ALTER TABLE ATMTXN
ADD CONSTRAINT VALID_ACCOUNT
FOREIGN KEY DEPT (ACCTID) REFERENCES ACCT_MASTER
ON DELETE NO ACTION
To delete a
constraint with SQL, use the DROP instruction:
ALTER TABLE ATMTXN
DROP CONSTRAINT NO_NEGATIVE_BAL
Implementing Triggers
on Existing Systems
Think again of the hypothetical situation described at the
beginning of the article: Put yourself in the position where you are suddenly
promoted to the position of "IT
manager" in a shop with a system which has been "somewhat
reliable" for many years, with some "known bugs ".
Having read the above article, you now know that triggers
are endlessly reliable business-rule/data-integrity enforcers. You also know that placing rule-enforcing
triggers on some of your strategic, high-volume transaction files would
probably paralyze your "somewhat reliable" system, and that, at the
most inconvenient time, like month-end for example. Who needs that? Would you, newly minted IT manager want to
risk your neck because of a trigger program was too smart for its own good and
crashed your month-end for data integrity reasons? Should you leave good enough
alone? Could triggers help or would they be too radical a method to try to
boost the reliability of the system?
Whether the consequences could be considered minor or major,
there is something to be gained by enforcing basic database and business rules
with triggers. In the situation such as
the one described above, installing a trigger that would suddenly enforce referential
integrity could indeed paralyze the system described above. Does that mean you cannot use this technique
on an older system? The answer is NO.
The way to implement referential integrity in such a
situation is to start gradually. By this, I mean that you would want, as a
first pass, to create a trigger that would simply "ring the alarm" as
opposed to stop a process or a write or an update.
Here is what we mean: When a violation would occur, rather
than stopping the entire transaction, the trigger would simply write a record
in a log file, describing the type of violation that has occurred, with a
before and after image of the record. Having that information, one can target
the buggy programs, fix them and only when the program has proven to be
reliable for an appropriate period of time (look at the log file to determine
that) then and only then, implement a trigger that would enforce the
rules.
Existing Triggers: Know What You Have
On Your System
One question you may not have thought of is "Are there
triggers present on your system right now?" You can get the answer to this question by
typing the following command:
PRTTRGPGM LIB(*ALL) CHGRPTONLY(*NO)
Be prepared
to see this command running for a long time. It may be advisable to submit it
in batch mode. If you do get results in that listing, review them carefully and
ensure you understand what each one of these triggers does. While trigger programs can be excellent
guardians of data integrity, they are essentially programs that "react to
events". They also tend not to attract attention to themselves, as they
are not called directly by any other program, CL or otherwise, which means they
don't tend to come up in cross-reference listings.
This makes
trigger programs good candidates for hiding malicious code. While the iSeries
has a reputation for being virus-proof, because of their nature, it is good
practice for the technical manager to know exactly what triggers reside on
their system and what action these triggers will take, who compiled them when,
etc.
Once you
have seen the base line report, done with the command above you can then
periodically run the same command, just changing the CHGRPTONLY parameter to
*YES. This version of the report will list changes and new trigger programs on
your system.
In the same
vein, When an SQL trigger is created, its definition is automatically added to
the SYSTRIGGERS, SYSTRIGDEP, SYSTRIGCOL, and SYSTRIGUPD catalogs. In the same
way, when an SQL table is restored, the definitions for the SQL triggers are
also restored, along with their definitions in those catalogs, which can be
queried with SQL. The idea here, once again, is to know exactly what you have
on your system, as far as trigger objects, written with a high-level language
or with SQL, and what each trigger program does.
Triggers and Performance Impact
Considerations
Performance
considerations, especially on large databases, are critical. Assume you have a
database file, used for add or update by ten different programs, each of which
using the exact same edit. If you take the edit portion of the code out each of
these programs and write it instead (only once this time) in a trigger program,
the performance impact should be minimal. The same edit will be performed for
each add or update, only at a different level. If the edits, implemented as
triggers, are completely new however, there will be an impact. Also, one has to
be conscious that adding cascading or nested triggers on a database file where
there was none before can translate into a noticeable performance
downgrade.
In Conclusion
Triggers are not used as often as they could be. Perhaps
because most programmers can simply live with some margin of error in dealing
with the applications they are currently working on. Ask yourself: Could your system be more
reliable? Do you get called occasionally in the middle of the night for
problems caused by bad data?
If you can answer yes to either of these questions, then
triggers may be worth exploring in your shop.
We would encourage anyone who has managed to live without
triggers until now to find a spot where there may be place for improvement in
their system. What is there to lose?
Can you use
a promotion? Can you use a salary increase? Triggers are all about helping developers
improve system reliability. Working with reliable systems mean you can be busy
being productive instead of reacting to avoidable bugs. At the end of the day, who will be the first
to benefit from greater system reliability in your organization?
The answer
is simply YOU!
Appendix 1: Trigger Commands (credit: IBM
iSeries
Required authorities
and data capabilities for triggers
To add a
trigger, you must have the following authorities:
Object
management or Alter authority to the file
Read data
rights to the file
Corresponding
data right relative to trigger event
Execute authority
to the file's library
Execute
authority to the trigger program
Execute
authority to the trigger program's library
The file
must have appropriate data capabilities before you add a trigger:
CRTPF
ALWUPD(*NO) conflicts with *UPDATE Trigger
CRTPF
ALWDLT(*NO) conflicts with *DELETE Trigger
ADDPFTRG is
the Add Physical File Trigger
Displaying Triggers
The Display File Description (DSPFD) command provides a list
of the triggers that are associated with a file. Specify TYPE(*TRG) or TYPE(*ALL)
to get this list. The command provides the following information:
Ø
The
number of trigger programs
Ø
The
trigger program names and libraries
Ø
The
trigger events
Ø
The
trigger times
Ø
The
trigger update conditions
Removing Triggers:
Use the Remove Physical File Trigger (RMVPFTRG) command to
remove the association of a file and trigger program. Once you remove the
association, the system takes no action when a change is made to the physical
file. The trigger program, however, remains on the system.
Credits:
IBM, Stored
Procedures, Triggers and User Defined Functions on DB2 Universal Database for
iSeries (http://www.redbooks.ibm.com/redbooks/pdfs/sg246503.pdf)